Scan
Scanned count and bytes retrieved is used for calculating the RRU consumed for the scan. For a large tables pagination is carried out cost may be high.
Scan operation reads all the items from a table. If the number/size of the items is such that it cannot be accomodated in a single page of 16 MB then the response for additional pages need to be retrieved as explained under the Pagination topic.
By default the table scan is sequential. That is items are read from one partition at a time and returned to the caller. For improving the scan performance you can use Parallel Scan.
Example here illustrates the use of Filter Expression and Expression Attribute Values. Scan retrieves all items for the table but returns only those items in which the employee’s manager loginalias is equal to johns.
aws dynamodb scan \
--table-name Employee \
--filter-expression 'ManagerLoginAlias = :managerAlias' \
--expression-attribute-values '{":managerAlias": {"S": "johns"}}'
Parallel scan
For tables with large number of items, the sequential scan may lead to unacceptable performance. For that reason, DynamoDB also support parallel scan. Application can initiate reads from multiple partitions in parallel. Application decides on the number of threads to use for this type of scan. This can give a considerable performance boost to an application that needs access to large number of items within a short timespan.
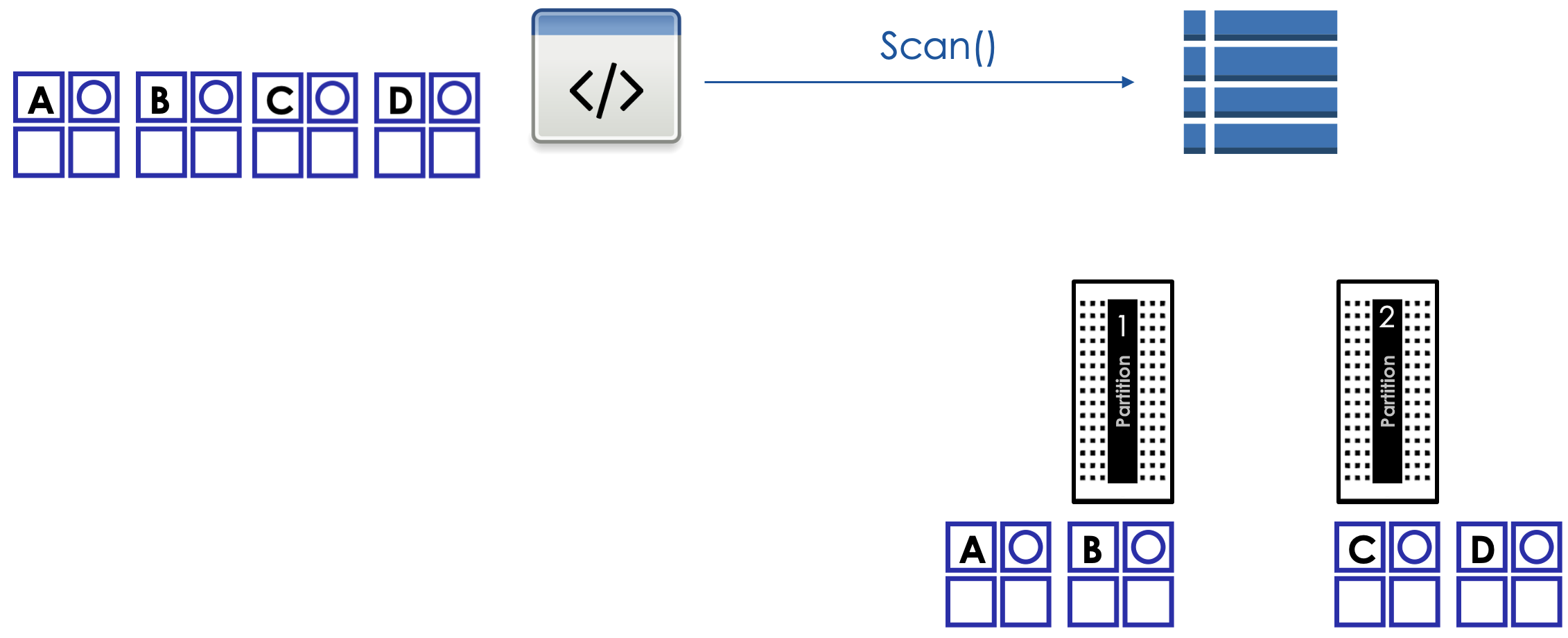
In the illustration below, user has sepcified 2 parallel threads for retrieval. Compared to a sequential scan, this will cut down the retrieval time by roughly 50% as a sequential scan uses a single thread.

Scan operation
The Scan operation returns one or more items and item attributes by accessing every item in a table or a secondary index.
-
TableName is a required parameter
-
IndexName is for scanning a table
-
Limit is the maximum number of items to evaluate. If DynamoDB processes the number of items up to the limit while processing the results, it stops the operation and returns the matching values up to that point, and a key in LastEvaluatedKey to apply in a subsequent operation.
-
ProjectionExpression comma separated string with one or more attribute names to be retrieved
-
FilterExpression specifies the item selection criteria
-
ScanIndexForward specifies the order for index traversal: If true (default), the traversal is performed in ascending order; if false, the traversal is performed in descending order.
-
Select specifies the attributes to be returned in the result.
-
ALL_ATTRIBUTES If you query a local secondary index, then for each matching item in the index, DynamoDB fetches the entire item from the parent table.
-
ALL_PROJECTED_ATTRIBUTES applies to the index; returns the attributes projected in the index
-
COUNT returns the number of matching items
-
SPECIFIC_ATTRIBUTES is equivalent to ProjectionExpression
-
-
TotalSegments applies to parallel scan; it represents the total number of segments into which the Scan operation will be divided; think of it as the number of threads to be used for parallel scan
-
Segment applies to parallel scan; it identifies an individual segment to be scanned by an application worker.
Example for Parallel Scan
In this example Python code below, application is initiating a parallel scan with 3 threads. Each thread independently receieves all pages by making multiple calls to the scan operation using the LastEvaluatedKey
import boto3
import time
import sys
import json
import threading
# Parameters that may be adjusted
TABLE_NAME=''
LIMIT=1000
FILTER="SK=:letter"
ATTR_VALUES={":letter":"M"}
PROJECTIONS='PK,SK'
# Number of threads
TOTAL_SEGMENTS=3
# Decides if items are printed
ITEM_PRINT_FLAG=False
args = sys.argv[1:]
TABLE_NAME = args[0]
if len(args) > 1:
ITEM_PRINT_FLAG=True
items=[]
# 1. Scan the table with segment specification
def scan_in_segments(segment):
boto_args = {'service_name': 'dynamodb'}
dynamodb = boto3.resource(**boto_args)
table = dynamodb.Table(TABLE_NAME)
count=0
scanned_count=0
# Record begin time
begin_time = time.time()
response = table.scan(
FilterExpression=FILTER,
ExpressionAttributeValues=ATTR_VALUES,
Limit=LIMIT,
ProjectionExpression=PROJECTIONS,
TotalSegments=TOTAL_SEGMENTS,
Segment=segment)
# Add items if printing is needed
if ITEM_PRINT_FLAG:
items.append(response['Items'])
# Update the counts
count = count + response['Count']
scanned_count = scanned_count + response['ScannedCount']
# Gather all pages
while 'LastEvaluatedKey' in response:
response = table.scan(
FilterExpression=FILTER,
ExpressionAttributeValues=ATTR_VALUES,
Limit=LIMIT,
ExclusiveStartKey=response['LastEvaluatedKey'],
ProjectionExpression=PROJECTIONS,
TotalSegments=TOTAL_SEGMENTS,
Segment=segment)
if ITEM_PRINT_FLAG:
items.append(response['Items'])
# Update the counts
count = count + response['Count']
scanned_count = scanned_count + response['ScannedCount']
# Record begin time
end_time = time.time()
# returns the counts
return count, scanned_count, (end_time - begin_time)
# 2. Target Function - target for the thread
def thread_scan_function(segment):
dat = scan_in_segments(segment)
thread_stats.append(dat)
# 3. Create the threads and start
thread_stats=[]
thread_list = []
for i in range(TOTAL_SEGMENTS):
thread = threading.Thread(target=thread_scan_function, args=[i])
thread.start()
thread_list.append(thread)
time.sleep(.1)
# Join the thread to the main thread
for thread in thread_list:
thread.join()
# 4. Consolidate the stats/results
TOTAL_COUNT=0
TOTAL_SCANNED_COUNT=0
TOTAL_TIME=0
MAX_THREAD_TIME=0
for dat in thread_stats:
TOTAL_COUNT = TOTAL_COUNT+dat[0]
TOTAL_SCANNED_COUNT = TOTAL_SCANNED_COUNT+dat[1]
TOTAL_TIME = TOTAL_TIME + dat[2]
if dat[2] > MAX_THREAD_TIME:
MAX_THREAD_TIME=dat[2]
AVERAGE_THREAD_TIME = TOTAL_TIME/TOTAL_SEGMENTS
# Print the items
if ITEM_PRINT_FLAG:
print(items)
# Print the stats
print ('PARALLEL Scan: Count=%i ScannedCount=%i AVG Thread-time =%s seconds MAX Thread-time=%s seconds' % (TOTAL_COUNT, TOTAL_SCANNED_COUNT, round(AVERAGE_THREAD_TIME,2),round(MAX_THREAD_TIME,2)))