Secondary Indexes
A Secondary Index is a data structure that contains subset of attributes from a table, along with alternate key support for query operations. Indexes may be scanned and queried like a table.
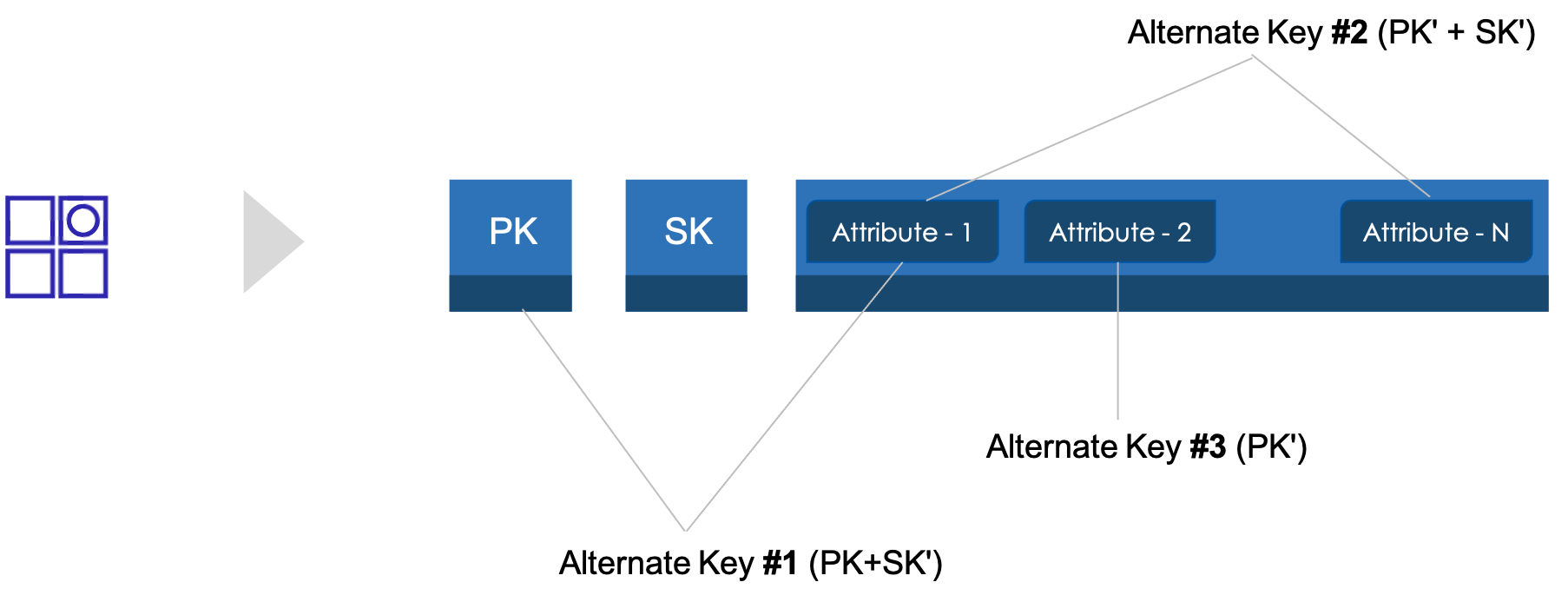
Alternate keys
A table is always created with a key-schema and attributes in the key schema MUST be defined at the time of table creation. Index requires a key-schema that uses at least one non-key attribute for the table. What that means is that you may select a table’s key and non-key attributes to define the key schema for the index.
Example Key#1 is an alternate index key that uses the Partition Key of the base table and non-key Attribute-1
Example Key#2 is an alternate index key that using ONLY non-key attributes from the base table
Example Key#3 an alternate index key that is using just the non-key attribute-2 ; it’s a simple primary key
Relational DB Index
Though the Relational Database Indexes and DynamoDB indexes use similar data structure (B-Tree) and have the same objective of achieving better query performance, they operate and are used differently.
Typically, relational database Indexes are implemented using a data structure known as B-Tree. When an index is created on the key column in a table, DB engine uses the Btree data structure to organize the index data - the key column from the table is used for index’s sort order and it points to a record in the relational database table. In short the Index key is mapped to a pointer structure that points to the records in the table.
DynamoDB Index
DynamodDB indexes also use the B-tree data structure like a relational database. The key difference is that DynamoDB indexes duplicates the data in the index rather than using a pointer to the item. This strategy leads to pre-joined data in physical storage. At run time there are no overheads for de-refereing the index pointer to actual data. By using index projections You control the attributes that get duplicated to the index.
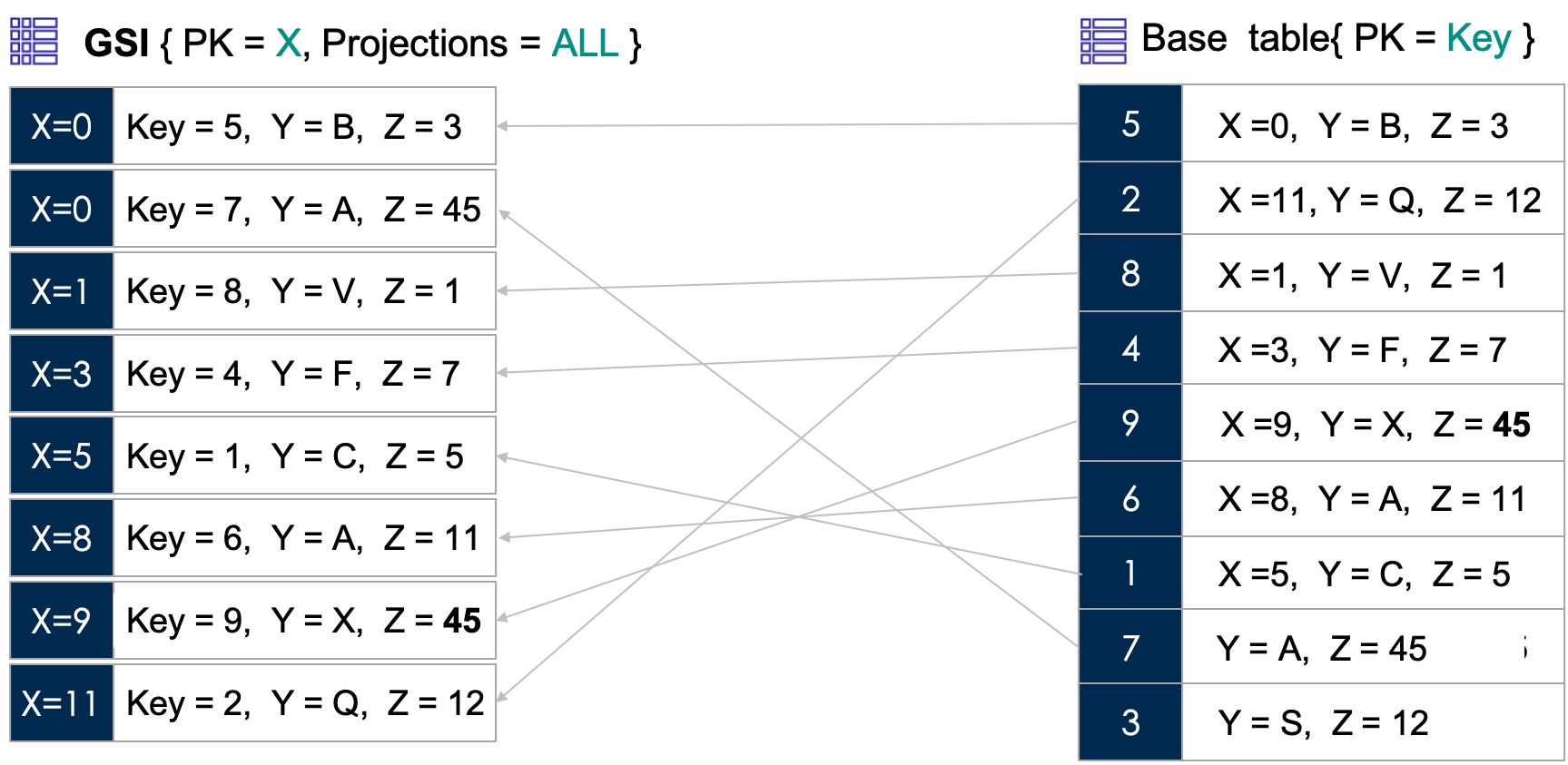
Illustration below depicts a scenario in which the non-key attribute x in base table is used as the index-key. Projections for the index is set to ALL, as a result all attributes are getting copied to the index data-structure.
Index key uniqueness
Is NOT enforced and that means you may have multiple items in the Index with the same key values. Checkout the index structure in the illustration for X=0
Index sparseness
If the alternate key attribute is missing in the item then it is not propagated to the index. Checkout the item in base table with Partition Key = 3; it is not propagated to the index.
In general:
- Capacity mode for index is the same as base table
- Indexes get deleted when the table is deleted
- Write capacity is used when data is written to an index.
- No impact on table write performance as replicaton is asynchronous
Index definition
An index definition has 2 parts.
- Key schema that specifies the alternate key
- Projections decide the attributes that are duplicated. It is a list of attributes from the base table that become available in the query and scan on index.
- ALL will duplicate all attributes
- INCLUDE specific attributes in the index
- KEYS_ONLY that only deplicates the alternate key attributes